

✍️ Manipulation with Two-Stage Training#
This example demonstrates robotic manipulation using a two-stage training paradigm that combines reinforcement learning (RL) and imitation learning (IL). The central idea is to first train a privileged teacher policy using full state information, and then distill that knowledge into a vision-based student policy that relies on camera observations (and optionally robot proprioception). This approach enables efficient learning in simulation while bridging the gap toward real-world deployment where privileged states are unavailable.
Environment Overview#
The manipulation environment is composed of the following elements:
Robot: A 7-DoF Franka Panda arm with a parallel-jaw gripper.
Object: A box with randomized initial position and orientation, ensuring diverse training scenarios.
Cameras: Two stereo RGB cameras (left and right) facing the manipulation scene. Here, we use Madrona Enginer for batch rendering.
Observations:
Privileged state: End-effector pose and object pose (used only during teacher training).
Vision state: Stereo RGB images (used by the student policy).
Actions: 6-DoF delta end-effector pose commands (3D position + orientation).
Rewards: A keypoint alignment reward is used. This defines reference keypoints between the gripper and the object, encouraging the gripper to align to a graspable pose.
This formulation avoids dense shaping terms and directly encodes task success.
Only this reward is required for the policy to learn goal reaching.
RL Training (Stage 1: Teacher Policy)#
In the first stage, we train a teacher policy using Proximal Policy Optimization (PPO) from the RSL-RL library.
Setup:
pip install tensorboard rsl-rl-lib==2.2.4
Training:
python examples/manipulation/grasp_train.py --stage=rl
Monitoring:
tensorboard --logdir=logs
The reward learning curve looks like the following if the training is successful:
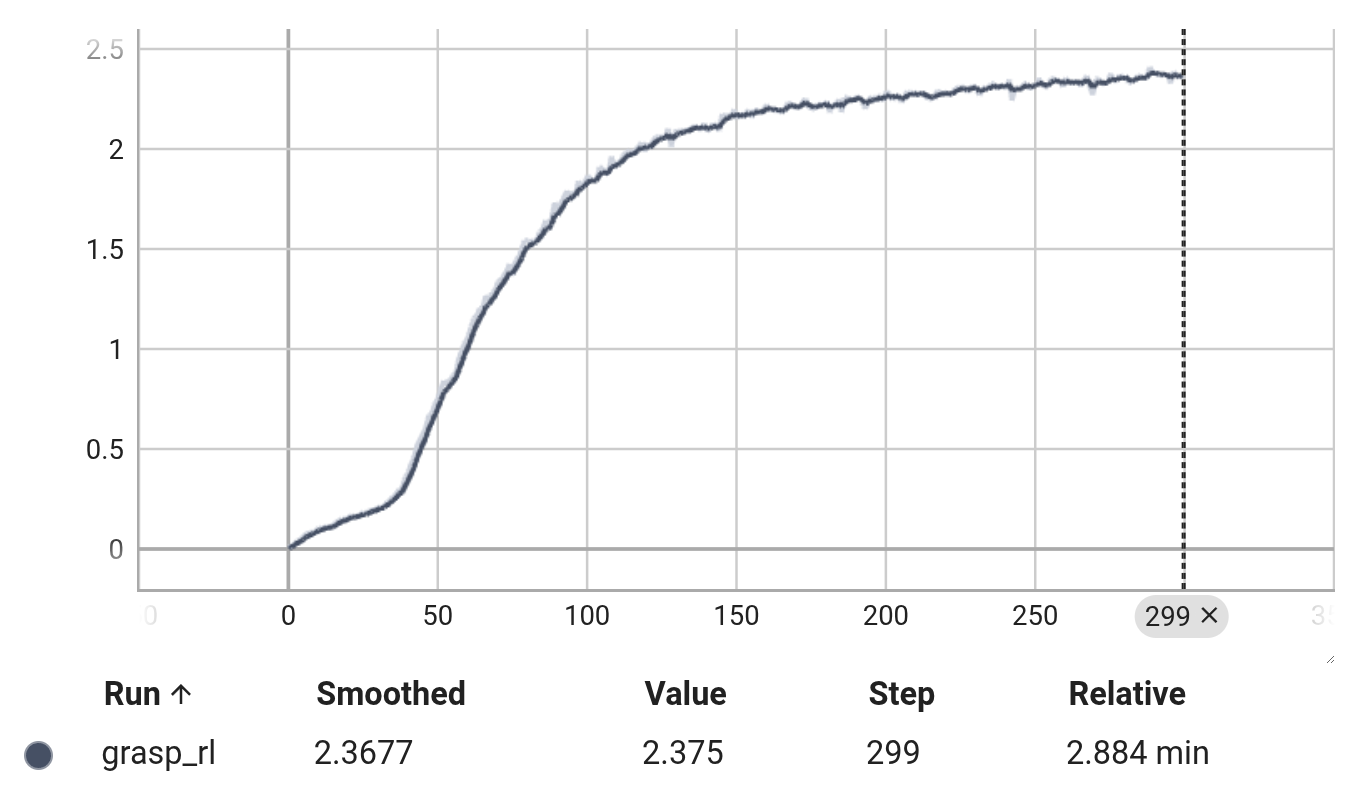
Key details:
Inputs: Privileged state (no images).
Outputs: End-effector action commands.
Parallelization: Large vectorized rollouts (e.g., 1024–4096 envs) for fast throughput.
Reward design: Keypoint alignment suffices to produce consistent grasping behavior.
Outcome: A lightweight MLP policy that learns stable grasping given ground-truth state information.
The teacher policy serves as the demonstration source for the next stage.
Imitation Learning (Stage 2: Student Policy)#
The second stage trains a vision-conditioned student policy that imitates the RL teacher.
Architecture:
Encoder: Shared stereo CNN encoder extracts visual features.
Fusion network: Merges image features with optional robot proprioception.
Heads:
Action head: Predicts 6-DoF manipulation actions.
Pose head: Auxiliary task to predict object pose (xyz + quaternion).
Training Objective:
Loss:
Action MSE (student vs teacher).
Pose loss = position MSE + quaternion distance.
Data Collection: Teacher provides online supervision, optionally with DAgger-style corrections to mitigate covariate shift.
Outcome: A vision-only policy capable of generalizing grasping behavior without access to privileged states.
Run training:
python examples/manipulation/grasp_train.py --stage=bc
Evaluation#
Both teacher and student policies can be evaluated in simulation (with or without visualization).
Teacher Policy (MLP):
python examples/manipulation/grasp_eval.py --stage=rl
Student Policy (CNN+MLP):
python examples/manipulation/grasp_eval.py --stage=bc --record
The student observes the environment via stereo cameras rendered with Mandrona.
Logging & Monitoring:
Metrics recorded in TensorBoard (
logs/grasp_rl/orlogs/grasp_bc/).Periodic checkpoints for both RL and BC stages.
Summary#
This two-stage pipeline illustrates a practical strategy for robotic manipulation:
Teacher policy (RL): Efficient learning with full information.
Student policy (IL): Vision-based control distilled from demonstrations.
The result is a policy that is both sample-efficient in training and robust to realistic perception inputs.